
Data mesh is a decentralized approach to data architecture that has recently increased in popularity. Within the data mesh approach, data ownership is handed to the domain or business function that best understands the data's structure, purpose, and value. With this ownership comes the responsibility of each team to ensure that the data is clean, free of errors, and accessible to others.
Centralized vs. decentralized data approach
For the past 20 years, the prevailing notion around data has been that it is best handled using a centralized data ecosystem. Ever-increasing computing power and decreasing data storage and processing costs incentivized companies to centralize their data collection.
Most organizations store this centralized data in a data warehouse or data lake where a specialized team of data engineers maintains the pipelines and data cleaning. This means that the centralized team is responsible for most (if not all) of data-related functions, including extracting, maintaining, cleaning, and loading data into tools that business users can utilize.
The rise of data mesh
Data mesh offers a fundamentally different answer to the question of data management.
Essentially, each business domain should treat its data as a product they make available to the rest of the organization. This creates a node-like system where ownership of the data is retained within specific teams, but the output is accessible by other parts of the organization in a mesh-like structure.
In this article, we will look at these different approaches to data architecture and what you need to keep in mind when deciding which path to choose in your organization.
Data mesh vs. centralized architecture
The rising interest in data mesh is partly explained by looking at a centralized approach's past, present, and future challenges (data warehouses or data lakes). In hindsight, the appeal of central data storage seems obvious.
On its surface, it allowed organizations to better handle the increasing volume of data at scale. It broke down information silos in companies by making data more readily available to users outside specific domains. However, upon closer inspection, this solution comes with its challenges.
The proliferation of data
In any company today, the potential availability of data is vast. In marketing alone, the median number of data sources for a B2C company in 2021 was 10, up from 6 just one year prior and projected to increase to 12 during 2022. Based on this trajectory, that number will likely jump into the twenties in just a few years.
A fully centralized approach creates some headaches for a central data team. In addition to building and maintaining an ever-growing data pipeline, the raw data output from different platforms is rarely uniform or standardized. Without sufficient domain expertise, it can be tough to assess how the data needs to be cleaned and transformed to generate usable output.
The risk of stifling innovation
The increasing availability of data also creates intriguing opportunities to mine for patterns, correlations, or even causative relationships between data points. This possibility for rapid innovation needs to be nurtured. But with a centralized approach, with one team responsible for the entire company data stack, chances are that the availability of internal resources blocks any required additions or changes to the data pipeline or transformation layer.
Outside of the stifling of innovation, this can become a source of organizational frustration, which carries significant long-term risks for the company culture and levels of trust.
On the flip side, a data mesh infrastructure can offer teams more autonomy by being able to self-service their data needs. The image below from Scott Brinker at Chief Martech highlights the impact of having a self-service approach as opposed to a centralized one – where in the latter, a lot of time is wasted just waiting for things to be done.
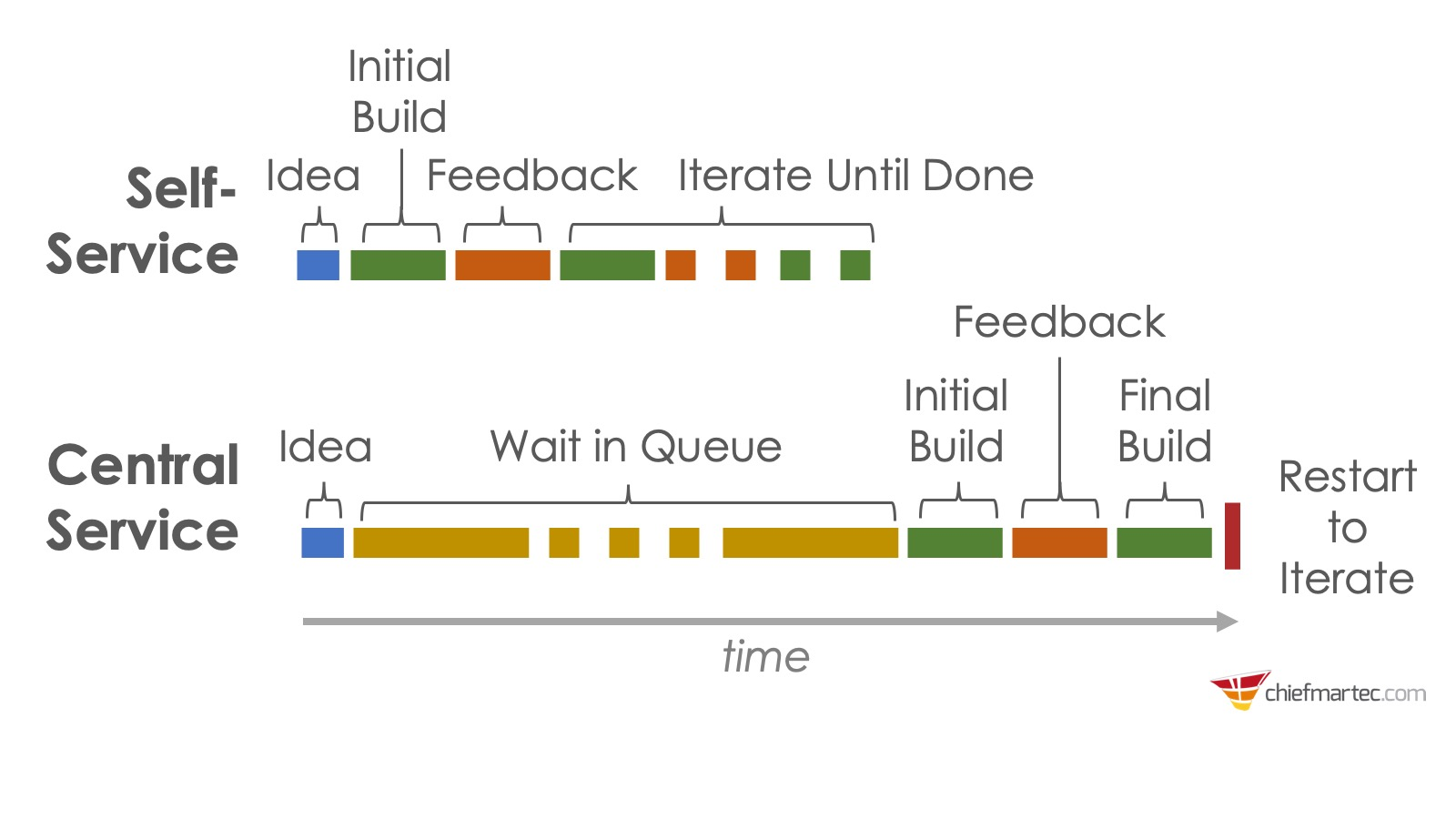
Decentralized ownership of data
As mentioned at the start of this article, the interest in data mesh has grown significantly in response to the frustrations of having tested a centralized or big data architecture.
In a data mesh architecture, ownership of a data asset or domain is decentralized and given to the business units most familiar with its structure, purpose, and value. With this ownership comes the responsibility of each team to ensure that the data is clean and free of errors so that other stakeholders can use it.
Instead of having a centralized team of data engineers and data scientists responsible for the entire data stack, they are scattered across the organization and work closely with the respective teams' domain experts. This will help ensure that the output is usable and understandable by the rest of the organization.
What are the benefits of data mesh?
With proper implementation, a data mesh architecture can help relieve many of the pains of a centralized approach by shortening waiting times, speeding up innovation cycles, increasing organizational trust, and improving output.
With these potential organizational benefits, it’s easy to see why interest in data mesh architecture has become popular in recent years. This trend will likely continue for years to come.
What are the benefits of data mesh for a marketing organization?
The decision to select an overall data architecture should be taken seriously and will depend on several factors.
As we’ve seen in this article, marketing teams that are part of organizations with a centralized data architecture can suffer from long waiting times, which slows the team's pace of innovation and testing frequency. Moreover, the number of data platforms and clouds marketing teams work with (and want to collect data from) keeps expanding yearly.
Data governance
Moving data ownership closer to the marketing team (the data consumers in this case) can increase the team's efficiency. By doing this, you can remove several headaches that come along with a monolithic centralized data approach. Data mesh is the preferred form of data governance for many data-driven organizations.
What are the downsides of data mesh?
In this blog post so far, we went over the questions:
- What is data mesh?
- What are the benefits of data mesh?
Now, in order to tell you the complete story, it is time to also discuss the downsides of data mesh. For this we asked Lars Rönnbäck to shine his light on the topic. Here's what he shared:
"The data mesh is staking out a new path into a decentralized data landscape. I fear that the data mesh will regress data management back into silos, where insights lose the big picture and tremendous effort will once again have to be put into combining information from autonomous data products in the mesh."
Rönnbäck also mentioned that implementation of a data mesh is very complex, and that most companies haven't been able to implement it as it was once described by Zhamak Dehgani: "Its [data mesh] data products are incredibly complex constructs. These products require data to be stored in a bitemporal model and also require that the data can be served in a variety of formats."
Further reading
Here are some handpicked blog posts you might be interested in:
- Everything you need to know about data mapping techniques: Guide to data mapping.
- What is a data mesh? Understand what data mesh is, how it affects marketing, and what its true business value is.
- What is a marketing data warehouse: All you need to know about data warehousing.
- An introduction to data models (with an example): Data modeling explained.